ruby + selenium webdriverチュートリアル
本エントリーは、Selenium/Appium Advent Calendar 2019 25日目エントリーです。
いい感じのチュートリアルがないので自分で作ります
近頃、自動化とかRPA系のイベントで登壇とかしているせいか、私への弟子入り志願者が増えています。
私としてはとても嬉しいですし、育ってくれたら仕事を手伝っていただきたいという気持ちですが、
プログラミングの学習サービスは数あれど、seleniumに関するオンライン学習となるとなかなか良いものがありません。
毎回1から教えていると時間がいくらあっても足りません。
そもそも業務効率化の事業をしているのに、全然効率的ではない。
ある程度体系化したものを自分で作って、最初はそのチュートリアルをやってみてもらうということにしました。
この記事は私のnoteでも公開します。
https://note.mu/katsuyads/n/nb833f7a06b57
noteでは2980円とさせていただきますので、もしこのチュートリアルが役に立ったということでしたら購入していただけるとこのブログのサーバー代くらいにはなるかと思います。
更に購入していただいた方にはコメント欄にて質問に回答させていただきます。
もちろん購入していただかなくても全く問題ありません。
このチュートリアルでは基本からseleniumでスクレイピングできるようになるところまでを扱います。
出力はcsvにして、エクセルで開いても文字化けしないというところまで作り込みます。
このチュートリアルを行う前提
チュートリアルを行う上で以下を理解している前提とします。
rubyのif文、loop文、each文、配列を理解している
ドットインストールやprogateなど無料で学べるサービスもあります。
他の言語の知見がある方はすぐに習得可能だと思います。
なんとなくわかったという方でも進められるかもしれません。
環境
|
1 2 3 |
ruby 2.3.3 selenium-webdriver最新バージョン chromedriver最新バージョン |
rubyの新しいバージョンだと私がよく使うimage magickがうまく動かないので2.3.3にしています。
selenium webdriverは最新が一番安定しており、
chromedriverはネイティブのchromeのバージョンがあがると古いものは上手く動かなくなるので最新にしてください。
windowsの環境構築は以下で紹介しています。
windowsならruby + selenium webdriverも環境設定は15分で終わる
macの場合はなんでもいいですが、
home brew入れて、rbenv入れて、ruby 2.3.3入れて、
gem install selenium-webdriver して、
brew cask install chromedriver すればいいと思います。
目次
チュートリアル3 – セレクターを指定して要素にアクセスする
チュートリアル1 – driverを宣言する
ではselenium-webdriverをrubyで動かしてみましょう。
selenium.rb というファイルを作ってテキストエディタで開いてください。
まずはselenium-webdriverを読み込んでchrome driverを立ち上げてみましょう。
dという変数にchrome driverを宣言します。
sleepを3秒入れて3秒間表示させてみましょう。
|
1 2 3 4 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome sleep 3 |
この状態で保存して、selenium.rbのディレクトリに移動し、ruby selenium.rb で実行。
chromeが立ち上がって閉じたら成功です。
チュートリアル2 – URLにアクセスして表示させる
URLにアクセスするには get または navigate.to を使います。
先程の selenium.rb を以下のように書き換えてみてください。
|
1 2 3 4 5 6 7 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") # またはd.navigate.to("https://katsulog.tech/") sleep 3 |
このブログが表示されて3秒くらいで閉じたら成功です。
演習
さっきのコードを書き替えて、googleとyahooを表示させてみてください。
チュートリアル3 – セレクターを指定して要素にアクセスする
ここからが本番です。
seleniumを扱う上で絶対に避けられないのがdeveloper toolです。
このブログのTOPページの記事一覧でキーボードのF12を押してみましょう。
するとデベロッパーツールが表示されますね。
デベロッパーツールが表示された状態で
「環境構築不要で配布!ruby+seleniumのコードをexe化【chromedriver】」というところを右クリックしてみましょう。
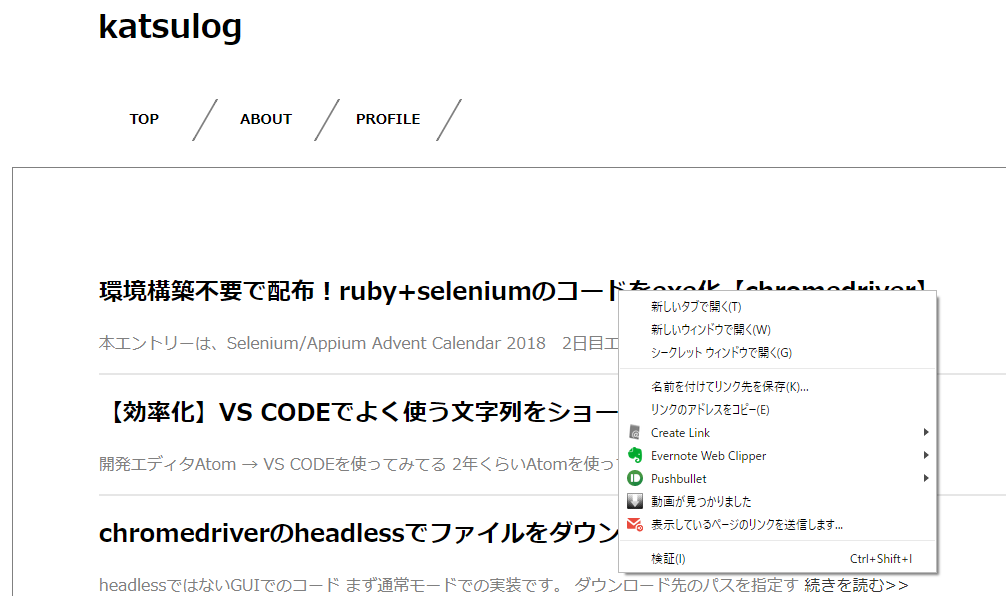
メニューの一番下に「検証」とあるので、ここをクリックしてください。
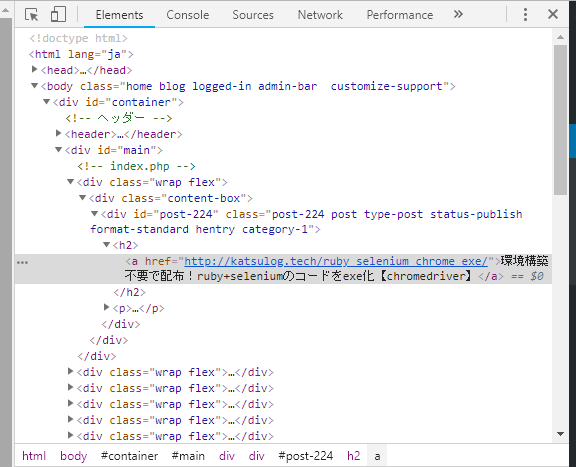
右クリックした要素がハイライトされましたね。
では、この要素を取得してみます。
ハイライトされた箇所の上を見ると「id=”post-224″」というコードがあります。
このようなものを「セレクター」と呼び、セレクターを利用して要素を取得していきます。
ではさっこく要素を取得してみましょう。
先程のselenium.rbを以下に書き換えてください。
|
1 2 3 4 5 6 7 8 9 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") puts d.find_element(:id, 'post-224').text sleep 3 |
実行してコマンドラインに
環境構築不要で配布!ruby+seleniumのコードをexe化【chromedriver】
本エントリーは、Selenium/Appium Advent Calendar 2018 2日目エン 続きを読む>>
と表示されたら成功です。
これは先ほどの要素をtextで表示するという命令です。
このようにセレクターを使って要素にアクセスし、その要素に命令をすることができます。
セレクターには以下のような種類があります。
・id
・name
・class
・css
・xpath
・tag_name
・link_text
・partial_link_text
先程はidを使いましたが、ソースを見るとclass=の中にもpost-224がありますね。というわけで
puts d.find_element(:class, ‘post-224’).text
に変えて実行しても同様の結果が表示されます。
ただし、classに関しては注意が必要で、HTMLではclassには同一のものを使用します。
post-224のclassは一つですが、その右にある「post」はいくつのもclassで使われています。
しかしidやnameについては原則1ページに1つしか使わないということがルール化されています(たまに複数使ってるところあるけど)。
こういった理由からセレクターにはできる限りidかnameを使うと良いでしょう。
その次にclassでそれ以降にcss、xpathといった感じです。取得スピードも違うそうです。
試しに以下に書き換えて実行してみてください。
「find_element」が「find_elements」になっているところに注意です。
|
1 2 3 4 5 6 7 8 9 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") puts d.find_elements(:class, 'post').count sleep 3 |
コマンドラインに
10
と表示されたら成功です。これはclass ‘post’がこのページで10個使われているということです。
また、find_element”s” のように複数系にすることによって要素が配列で返ってきます。
countすることで数を返しています。
配列が返るということは
d.find_elements(:class, ‘post’)[0]
d.find_elements(:class, ‘post’)[1]
d.find_elements(:class, ‘post’)[2]
のように添字をつけることでそれぞれを呼び出すことができます。
演習
d.find_elements(:class, ‘post’) を使用して、
【効率化】VS CODEでよく使う文字列をショートカットキーで登録
開発エディタAtom → VS CODEを使ってみてる 2年くらいAtomを使っていましたが、めっち 続きを読む>>
をコマンドラインに表示させてください。
ヒント:添字、.text
チュートリアル – 4 要素の継承
では要素の中から更に細かい要素にアクセスしてみましょう。
ブログTOPのソースを見てみます。
id=”post-224″ の配下に<h2>というタグがありますね。
これは記事のタイトル部分を表しています。
では取得してみましょう。
今回はtag_nameというセレクターを使用してみます。
|
1 2 3 4 5 6 7 8 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") puts d.find_element(:id, 'post-224').find_element(:tag_name, 'h2').text sleep 3 |
環境構築不要で配布!ruby+seleniumのコードをexe化【chromedriver】
がコマンドラインに表示されたら成功です。
このように要素を継承して更に細かい要素にアクセスすることが可能です。
演習
先程のid=”post-224″から
本エントリーは、Selenium/Appium Advent Calendar 2018 2日目エン 続きを読む>>
を出力してください。
ヒント:<p>
チュートリアル5 – 属性へのアクセス
ブログTOPの先程のソースを見てみると以下のようなコードがあります。
<a href=”http://katsulog.tech/ruby_selenium_chrome_exe/”>環境構築不要で配布!ruby+seleniumのコードをexe化【chromedriver】</a>
aタグの中にhrefという属性があって、その中に記事のURLが入っています。
ではこのURLを取得してみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") puts d.find_element(:id, 'post-224').find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") # これでもいけます。 # puts d.find_element(:id, 'post-224').find_element(:tag_name, 'a').attribute("href") sleep 3 |
コマンドラインにURLが出力されたら成功です。
このように属性にアクセスして取得することが可能です。
スクレイピングっぽくなってきましたね!
演習
id=”post-224″ のclassをコマンドラインに出力してみてください。
post-224 post type-post status-publish format-standard hentry category-1
が出力されたら成功です。
ヒント:書き足すだけではなく、階層を上げて属性を取得してみましょう。
チュートリアル6 – 配列で回す
次は要素を配列に入れて操作してみましょう。
要素を配列で取得するには find_elements を使いましたね。
では以下のように書いてみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") d.find_elements(:class, 'post').each do |post| puts post.find_element(:tag_name, 'h2').text end sleep 3 |
ブログTOPに表示されている記事すべてのタイトルがコマンドラインに出力されたら成功です。
では、次はURLを配列に入れて表示させてみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end urls.each do |url| puts url end sleep 3 |
コマンドラインにURLが10個出力されたら成功です。
演習
titlesという配列を宣言し、記事タイトルを10個titlesに格納した後にすべて出力してみましょう。
ヒント:配列をeachで回して1つずつ出力してください。
チュートリアル7 – デバック
デバックはプログラミングで超重要です。是非マスターしてください。
pryというgemもありますが、今回は標準で入っているdebugを使ってみます。
先程のコードの中にデバックを入れてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] d.find_elements(:class, 'post').each do |post| require 'debug' urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end urls.each do |url| puts url end sleep 3 |
以下のようにコマンドラインに出力されて止まりますね(rubyのバージョンが違うと表示のされ方が違います)。
|
1 2 |
./selenium.rb:10: urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") (rdb:1) |
配列のeachの最初で動きが止まった状態です。
試しにコマンドラインに post.text と入れて実行してみましょう。
ページの一番目の記事タイトルが表示されますね。
では n と打ち込んでみてください。
n はコードを1行進めることができます。一度 n を実行したら後はEnterキーを叩くたびに1行ずつ進んでいきます。
試しに n を2、3回叩いた後に post.text を入力してみてください。
先程と違うタイトルが表示されるはずです。
このようにコードを途中で止めてコードを実行することができます。
これはseleniumを実行するのに非常に重要なスキルになりますので、是非習得してください。
n 以外には c でコードを再開させられたり、q を叩いて確認メッセージで y を叩くとデバックを抜けられます。
qとyで抜けないとコードを実行できないので必ずデバックを抜けるようにしてください。
演習
urlsのeachの中にdebugを入れて変数urlの中身をコマンドラインに出力してみてください。
また、cでコードを再開させたり、デバックを抜けてみてください。
チュートリアル8 – ページャの移動
ここまででそれなりにスクレイピングできるようになりましたね。
ではページャをクリックしてページ移動し、最後のページまでURLを収集してみましょう。
ページャの「前へ」をデベロッパーツールで見てみると「class=”next page-numbers”」となっていますね。
では以下のようにコードを書き換えてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end d.find_element(:class, 'next page-numbers').click sleep 3 |
実行すると
invalid selector: Compound class names not permitted (Selenium::WebDriver::Error::InvalidSelectorError)
というエラーが出て落ちてしまいます。
これはclassというセレクターの中では複合クラス名は使えませんというエラーです。
このclassはスペースで区切られて next と page-numbers の2つのクラスがあるので、エラーになってしまいました。
こういう時はnextかpage-numbersのどちらかだけを使えばよいと思うのですが、
チュートリアル3でやったようにclassは複数の個所で使われている可能性があります。
こういう時はxpathを使ってみましょう。
デベロッパーツールで先ほどの個所を右クリックするとCopyというメニューの中にCopy XPathがいう項目があります。ここをクリックすることでxpathが取得できます。
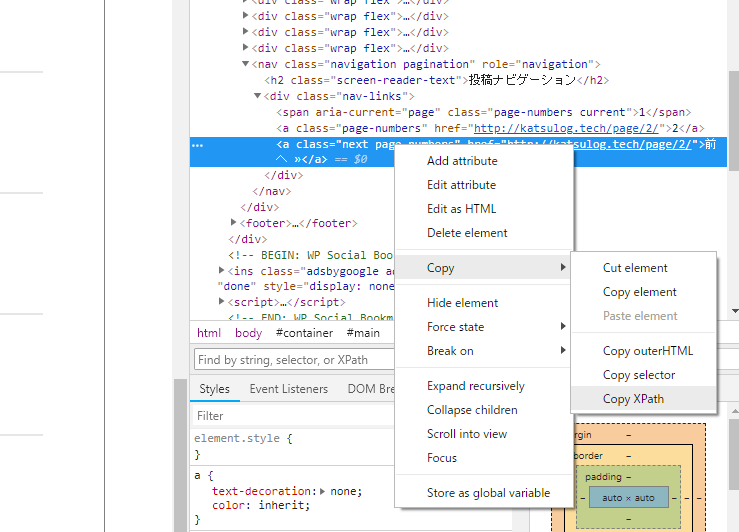
では先ほどのコードを修正しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end d.find_element(:xpath, '//*[@id="main"]/nav/div/a[2]').click sleep 3 |
実行すると2ページ目が表示されましたね。
演習
2ページ目に表示されている記事のURLをコマンドライン上に出力させてみてください。
チュートリアル9 – ループとブレイク
先程の演習ではどのようにコードを書きましたか?
こういう風に書いた人もいるのではないでしょうか。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end d.find_element(:xpath, '//*[@id="main"]/nav/div/a[2]').click urls = [] d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end urls.each do |url| puts url end sleep 3 |
これでもいいのですが、もしページが100ページくらいあった場合、コードがべらぼうに長くなってしまいます。
そこでループとブレイクを使ってURLを収集してみましょう。
以下のように書き換えてみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] loop do d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end if d.find_elements(:xpath, '//*[@class="next page-numbers"]').size > 0 d.find_element(:xpath, '//*[@class="next page-numbers"]').click else break end end urls.each do |url| puts url end sleep 3 |
プログラミングっぽくなってきましたね。if文とloop文とeach文が出て来るなんてかなりプログラミングっぽいです。
8行目から18行目までがループされています。16行目でbreakされています。
9行目から11行目までが表示されたページでURLをurlsに格納しています。
13行目では次のページにいくリンクが表示されているかをチェックしています。find_element”s”になっていることに注意です。
また、先ほどとxpathが違うことにも注目です。先ほどのxpathだと1ページ目と2ページ目を永遠に行き来するようになってしまっていました。
チュートリアル7でclassを見た時にnextとpage-numbersの2つがスペース区切りで入っていましたね。
そしてそれをそのままclassで書くとエラーになってしまいました。
しかしこのようにxpathで表現することによって正常に動作するようになります。これは呪文みたいなものなので覚えておいてください。
このブログでもxpathを利用する場合のtipsの記事があるので参考にしてください。
xpathについてのtips
さて、話を戻しますが、find_elementsにてこの要素の数を数えて、1以上だった時に14行目に入り、0だった時に16行目でloopをbreakしています。
14行目ではfind_elementでページャの要素にアクセスし、clickでクリックしています。これでページを遷移することができます。
クリックした後はまた9行目に戻ってURLを収集し、今度は次のページへいく要素がないのでbreakしてloopを抜けています。
あとは20~22行目で集めたすべてのURLをputsしていますね。
たったこれだけでこのブログのすべての記事のURLを収集することができてしまいました。
演習
記事のURLではなく、タイトルの文字列を収集してコマンドライン出力してみましょう。
ヒント:text
チュートリアル10 – 各ページへのアクセス
すべてのURLを収集することができるようになったので、今度はそのURLたちにアクセスしてみましょう。
以下のように書き換えてみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome d.get("https://katsulog.tech/") urls = [] loop do d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end if d.find_elements(:xpath, '//*[@class="next page-numbers"]').size > 0 d.find_element(:xpath, '//*[@class="next page-numbers"]').click else break end end urls.each do |url| d.get(url) end sleep 3 |
すべてのURLにアクセスしていますね。たのしー!
チュートリアル11 – waitの設定
要素のクリックや各ページへのアクセスをしてみるとその動きが高速であることがわかったと思います。
ただ、高速だからこそ、要素が現れる前にクリックしてしまったりしてエラーになってしまうことがあります。
そこでwaitを使ってみましょう。
以下のようにページを遷移した後に要素が現れるまで待つというコードを追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
require 'selenium-webdriver' d = Selenium::WebDriver.for :chrome wait = Selenium::WebDriver::Wait.new(:timeout => 10) d.get("https://katsulog.tech/") urls = [] loop do wait.until { d.find_elements(:class, 'post').size > 0 } d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end if d.find_elements(:xpath, '//*[@class="next page-numbers"]').size > 0 d.find_element(:xpath, '//*[@class="next page-numbers"]').click else break end end urls.each do |url| d.get(url) end sleep 3 |
driverの宣言の下でwaitを宣言しています。
wait.untilの中に書いてあることがtrueになるまで待つ、つまりclass=”post”が現れるまで待つということになります。
要素が表示されるまで待つとなると以下のようになります。
wait.until { d.find_element(:class, ‘post’).displayed? }
sleepで待つのではなく、waitを使った方が良いという記事を本ブログで書いていますので、こちらも読んでみてください。
要素を待つ時にsleepを使うのはオススメしない
演習
ページャをクリックする際にページャが表示されるまでwaitするというコードを追加してみてください。
ヒント:if文の中にwaitを入れる
チュートリアル12 – CSVに書き出す
さあスクレイピングの仕上げです。
各ページで表示されている要素をCSVに書き出しましょう。
まずはCSVを作成します。
以下のように書いてみてください。
|
1 2 3 4 5 6 7 8 9 10 |
require 'csv' bom = %w(EF BB BF).map { |e| e.hex.chr }.join csv_file = CSV.generate(bom) do |csv| csv << ["No", "Title", "URL"] end File.open("result.csv", "w") do |file| file.write(csv_file) end |
1行目でcsvライブラリを呼び出しています。
これを呼び出さないとselenium-webdriverと同様にcsvライブラリを使用できません。
3行目ではbomを宣言しています。
bomは「Byte Order Mark」の略で、UTF-8形式でcsvを作った際にbomをつけていないとエクセルで開いた時に日本語が文字化けしたりしてしまいます。
日本語を扱う際はbomをつけましょう。
4~6行目では宣言したbomを使ってcsvオブジェクトを作っています。csvファイルではなく、ここではまだオブジェクトです。
3行目ではNo、Title、URLという列を作っています。
そして8~10行目では先程作ったcsv_fileというオブジェクトをresult.csvに書き込んでいます。
csvファイルを作成する際は通常 CSV.open(“result.csv”, “w”) のようにするのですが、csvオブジェクトを書き出すためにFile.openになっています。
では、今まで書いたコードと合体させて、csvファイルに各ページのタイトルとURLを書きだしてみましょう。
以下のように書き直してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
require 'selenium-webdriver' require 'csv' bom = %w(EF BB BF).map { |e| e.hex.chr }.join csv_file = CSV.generate(bom) do |csv| csv << ["No", "Title", "URL"] end File.open("result.csv", "w") do |file| file.write(csv_file) end d = Selenium::WebDriver.for :chrome wait = Selenium::WebDriver::Wait.new(:timeout => 10) d.get("https://katsulog.tech/") urls = [] loop do wait.until { d.find_elements(:class, 'post').size > 0 } d.find_elements(:class, 'post').each do |post| urls << post.find_element(:tag_name, 'h2').find_element(:tag_name, 'a').attribute("href") end if d.find_elements(:xpath, '//*[@class="next page-numbers"]').size > 0 d.find_element(:xpath, '//*[@class="next page-numbers"]').click else break end end i = 1 urls.each do |url| d.get(url) title = d.find_element(:id, 'main').find_element(:tag_name, 'h2').text page_url = d.current_url CSV.open("result.csv", "a") do |file| file << [i, title, page_url] end i += 1 end |
実行するとresult.csvが出力されますね。これがスクレイピングの力です!
35行目でtitleに記事のタイトル、36行目でpage_urlに記事のURLを格納しています。
元々変数urlに記事のURLが入っているのですが、あえて現在のページのURLを取得する関数を使用してみました。
37~39行目でresult.csvに追加しています。
9行目では File.open(“result.csv”, “w”) としているのですが、
37行目では CSV.open(“result.csv”, “a”) としています。
w はwriteの略だと思うのですが、丸っと上書きしてしまうのに対して、
a はaddの略で、行を追加していくという意味になります。
そして38行目で行にNoとTitleとURLを書き込んでいます。
40行目でi += 1しているので、次に入ってくるiはプラス1された数値になっています。
演習
csvファイルに「selenium」というカラムを追加して、各行で「最高」という文字列を決め打ちで出力してみてください。
ヒント:宣言時と追加時を書き換える
最後に
お疲れさまでした!
これでスクレイピングの基本的なことを学べただけではなく、
selenium webdriverの広い範囲を身につけられたということになります。
もちろん、seleniumもプログラミングもまだまだできることがあるのですが、
自分でいろんなサイトで試してみることで実力があがっていくと思います。
他にも
d.find_element(:name, ‘s’).send_key(“selenium”)
というコードを実行するとブログの右上のサーチボックスにseleniumという文字が入力されたり、
できることはたくさんありますよ!
seleniumをやってみたいという方がいたら是非この記事を紹介してあげてください。
最後までお読みいただきましてありがとうございました。